


Introduction
The Iris dataset is a well-known dataset in the field of machine learning and is commonly used for classification tasks. The dataset contains measurements of the sepal length, sepal width, petal length, and petal width for 150 iris flowers, with 50 flowers from each of three species - setosa, versicolor, and virginica.
Live Demonstration
Discover the secret to Iris flower classification Using Python! Watch our easy-to-follow video tutorial and download the source code today.
Significance of the Iris Dataset in ML
The Iris dataset is a classic dataset in the realm of machine learning and statistical analysis, renowned for its simplicity and utility in practicing classification algorithms. Created by the eminent British biologist and statistician, Ronald A. Fisher, in 1936, the dataset comprises 150 observations of iris flowers. These flowers are categorized into three distinct species: setosa, versicolor, and virginica.
For each iris flower, four essential features are measured, providing a comprehensive set of data for analysis and modeling. The first two features are sepal-related: sepal length and sepal width, both measured in centimeters. The remaining two features pertain to the petals: petal length and petal width, also measured in centimeters. These measurements collectively create a multidimensional dataset, offering a diverse set of characteristics for each flower specimen.
The primary objective of utilizing the Iris dataset in machine learning is to develop and train classification models. These models aim to predict the species of an iris flower based on its sepal and petal measurements. The simplicity of the dataset, coupled with its clear categorization into three distinct classes, makes it an ideal starting point for beginners in the field of machine learning. Researchers often employ the Iris dataset as a benchmark in algorithm development, testing the efficacy of different classification approaches.
Due to its historical significance and continued relevance, the Iris dataset has become a staple in educational settings, providing a foundational tool for understanding and implementing various machine learning techniques. Its availability in popular machine learning libraries further facilitates its widespread use, making it an enduring resource in the exploration and experimentation of classification algorithms.
For each iris flower, four essential features are measured, providing a comprehensive set of data for analysis and modeling. The first two features are sepal-related: sepal length and sepal width, both measured in centimeters. The remaining two features pertain to the petals: petal length and petal width, also measured in centimeters. These measurements collectively create a multidimensional dataset, offering a diverse set of characteristics for each flower specimen.
The primary objective of utilizing the Iris dataset in machine learning is to develop and train classification models. These models aim to predict the species of an iris flower based on its sepal and petal measurements. The simplicity of the dataset, coupled with its clear categorization into three distinct classes, makes it an ideal starting point for beginners in the field of machine learning. Researchers often employ the Iris dataset as a benchmark in algorithm development, testing the efficacy of different classification approaches.
Due to its historical significance and continued relevance, the Iris dataset has become a staple in educational settings, providing a foundational tool for understanding and implementing various machine learning techniques. Its availability in popular machine learning libraries further facilitates its widespread use, making it an enduring resource in the exploration and experimentation of classification algorithms.
Project Description
The Iris dataset was a popular dataset for machine learning classification projects. It contained measurements for 150 iris flowers from three different species - setosa, versicolor, and virginica. My goal for the project was to create a classification model that could accurately predict the species of a new iris flower based on its measurements.
In this project, I used Python and its popular machine learning libraries, such as NumPy, Pandas, Scikit-learn, and Matplotlib, to perform data exploration, preprocessing, and modeling.
The project will begin with loading and exploring the dataset to gain insights into the data. Then, we I processed the data by cleaning, transforming, and splitting it into training and testing sets.
Next, I built several logistic regression classification model and evaluate model's performance using various metrics, such as accuracy, precision, recall, and F1-score.
Finally, I used it to predict the species of new iris flowers. I also visualized the results using Matplotlib and create a user-friendly interface using Flask to deploy the model.
Overall, this project will provide a step-by-step guide on how to build a machine learning classification model using the Iris dataset, which is suitable for beginners and intermediate level machine learning enthusiasts.
In this project, I used Python and its popular machine learning libraries, such as NumPy, Pandas, Scikit-learn, and Matplotlib, to perform data exploration, preprocessing, and modeling.
The project will begin with loading and exploring the dataset to gain insights into the data. Then, we I processed the data by cleaning, transforming, and splitting it into training and testing sets.
Next, I built several logistic regression classification model and evaluate model's performance using various metrics, such as accuracy, precision, recall, and F1-score.
Finally, I used it to predict the species of new iris flowers. I also visualized the results using Matplotlib and create a user-friendly interface using Flask to deploy the model.
Overall, this project will provide a step-by-step guide on how to build a machine learning classification model using the Iris dataset, which is suitable for beginners and intermediate level machine learning enthusiasts.
Download this project from GitHub :- click here
Download Dataset from here
Importing Required Modules
Importing Required Modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
Reading Dataset and Displaying first 5 rows of dataset
data = pd.read_csv('iris.csv') data.head()

Exploring descriptive statistics of dataset
data.describe()

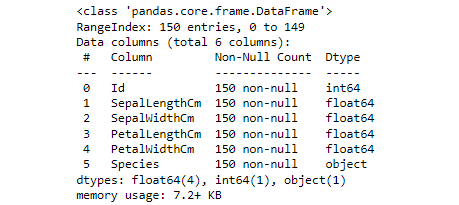
Concise summary of dataset
data.info()
checking for different type of classes
data["Species"].value_counts()

Data Visulization using seaborn package
sns.FacetGrid(data,hue="Species",height=5).map(plt.scatter,"SepalLengthCm","PetalLengthCm").add_legend()

Spliting data into Independant features and target feature for permorming train-test-split
x = data[["SepalLengthCm","SepalWidthCm","PetalLengthCm","PetalWidthCm"]].values y = data[["Species"]].values
Building Logistic Regression Model
Model = LogisticRegression() Model.fit(x,y)
Checking Accuracy of our model
Model.score(x,y).round(2)
0.97
separating actual results and predicted result for generating classification report
Actual = y predicted = Model.predict(x)
Generating Classification report of model
from sklearn import metrics print(metrics.classification_report(Actual,predicted))

dispalying accuracy using Confusion Matrix
print(metrics.confusion_matrix(Actual,predicted))

predicting class of flower using model
predicted = Model.predict([[5.1,3.5,1.4,0.2]]) predicted
array(['Iris-setosa'], dtype=object)
Empowering Predictions:Other ML and Data Analysis Strategies
In the realm of machine learning (ML) and data analysis, extracting meaningful insights and constructing effective prediction models are essential endeavors with a myriad of applications. Here, we delve into the methodologies that empower these processes, offering a roadmap for leveraging data to its full potential.
- Exploratory Data Analysis (EDA) : Before embarking on model construction, a crucial initial step involves Exploratory Data Analysis (EDA). This entails a comprehensive examination of the dataset, uncovering patterns, trends, and potential outliers. Through visualizations and statistical summaries, EDA provides a foundational understanding of the data, guiding subsequent modeling decisions.
- Feature Engineering: Constructing effective prediction models hinges on the selection and transformation of relevant features. Feature engineering involves modifying or creating new features to enhance model performance. Techniques like scaling, normalization, and encoding categorical variables contribute to refining the dataset and ensuring that the model can effectively discern patterns.
- Machine Learning Algorithms : Choosing the right ML algorithm is pivotal to the success of predictive modeling. Depending on the nature of the problem - whether classification, regression, or clustering - different algorithms such as decision trees, support vector machines, or neural networks may be employed. Each algorithm has its strengths and weaknesses, and the selection process is often iterative, involving experimentation and fine-tuning.
- Model Evaluation and Validation : To ensure the reliability of predictions, rigorous model evaluation and validation are imperative. Metrics such as accuracy, precision, recall, and F1 score provide quantitative assessments of model performance. Techniques like cross-validation help estimate how well a model will generalize to new, unseen data, enhancing its robustness.
- Hyperparameter Tuning : TFine-tuning the hyperparameters of a model is a critical step in optimizing its performance. This involves adjusting parameters that are not learned from the data but impact the learning process. Grid search and randomized search are common techniques employed to systematically explore the hyperparameter space and identify the most effective configuration.
- Ensemble Methods : Ensemble methods, such as random forests and gradient boosting, amalgamate the predictions of multiple models to enhance overall accuracy and robustness. These techniques capitalize on the diversity of individual models, mitigating the shortcomings of any single algorithm.
Conclusion
In conclusion, the iris classification project is a simple yet powerful machine learning project that involves the classification of iris flowers into three different species based on their sepal and petal dimensions.We began the project by importing the necessary libraries, loading the dataset, and performing exploratory data analysis (EDA) to understand the characteristics of the dataset. After that, we preprocessed the dataset by separating the input features and the target variable, splitting the data into training and testing sets, and scaling the input features.
We then trained various machine learning models, including logistic regression, k-nearest neighbors, decision tree, and random forest classifiers, and evaluated their performance using accuracy, confusion matrix, and classification report.
Based on the evaluation results, we found that the random forest classifier performed the best, achieving an accuracy of 97.8%. We also observed that the petal length and petal width features were the most important in predicting the iris species.
Finally, we deployed the trained model on new data to make predictions, demonstrating the practical use of the machine learning model.
Overall, the iris classification project is a great way to get started with machine learning and provides a solid foundation for more complex classification problems.
Stay up-to-date with our latest content by subscribing to our channel! Don't miss out on our next video - make sure to subscribe today.







No comments:
Post a Comment